
An interesting article in terms of the beginning of the fundamental shift from discrete physical models to computer modeling and simulation.
"Construction of STeLLA as a mechanical tortoise was abandoned when it became clear that with present technology and available resources the building of a machine could do no more than remind us of what we had once thought interesting! " .
As it turns out, there were still a few out there who took the 'real world' approach; otherwise my blog would have stopped here!
However, the key difference between STeLLA and other models of learning is that STeLLA uses Associative Learning, whilst most of the others use Behavioural Learning.
The below biography on John Andreae is an extract from http://www.elec.canterbury.ac.nz/purr_puss/biography.shtml .

John Andreae was born in 1927 in the Himalayan hill station Mussoorie in India.
His primary schooling was in England but secondary schooling back in India because of World War II.
He graduated BSc(Eng) in 1948 in Electrical Engineering at Imperial College, London and went on to PhD (1955).
Patents
J.H.Andreae and P.L.Joyce (1965): Learning Machine. Brit.Patents 1011685-7.
When ICI closed the Akers Research Laboratories in 1961, John found a new job and a new career at the Standard Telecommunication Laboratories in Harlow, Essex. Starting as "the electronic simulation of cerebral functions", the research soon became machine learning with the invention of his first learning machine STeLLA, named after the Laboratories. The design for STeLLA (pdf, 47.2KB) was published in 1963 at the Conference of the International Federation on Automatic Control in Basle, Switzerland, and in 2 patents with Peter L. Joyce. Much of STeLLA was constructed by Peter out of relays, but the unreliability of those relays led to its physical realization being abandoned and later research being based on computer simulation.

After contacting John in January 2010, he kindly provided the photo of STeLLA as well as the following words:
"STeLLA was named after Standard Telecommunication Laboratories (Learning Automaton) where I worked in Harlow, Essex, UK from 1961-6. It was built by Peter L Joyce using post office relays, which proved to be too unreliable. Of course, the real reason for not building hardware is that few people have the money and, when it is half built, you see that another design would be better!
My later system, PURR-PUSS (PP for short) had essentially the same structure as STeLLA with two important additions. Instead of actions being dependent on patterns of current stimuli, a multiple context made them dependent on the recent past in a much more comprehensive way. Also, PP sought novelty as well as reward. Apart from making PP much more teachable, novelty saved PP from the Gödel-Lucas-Penrose limitation on programmed machines. (My second book Associative Learning for a Robot Intelligence (1998) explains this and many other features.) "
I noted the antenna, so I had to ask if it was for a remote "brain" or for telemetry purposes. John responded: "Yes, it had to be remote because of the size of the relays it was made of and the large array of relays needed."
So the equipment behind the tortoise in the photo is the relay "brain" of STeLLA.
See John's site for further information on PURR-PUSS here.
Here's an extract on STeLLA from that site:
A Brief Look at STeLLA
In 1961, when my research began in what was a new area for me, called Cybernetics, there wasn't much doubt that any working model of the brain would have to learn from scratch: The tabula rasa, or blank slate, was how a machine that would learn like the brain had to start. Learning was what it was all about. Babies didn't know very much at all, if anything. A few years later things would change dramatically and by 1972 in the heyday of Artificial Intelligence (AI) people would be amazed by the programmed creations of Shortliffe (MYCIN), Lenat (AM), Winograd (SHRDLU) and others. For a while, it seemed to many as though that was the way to reveal the mysteries of the brain. That view was strongly supported by the new linguistics driven by Noam Chomsky and his argument that we are born with a Universal Grammar. However, I was not alone in finding the AI approach unconvincing and many people studying child development continued to doubt the amount of innate structure being assumed. Thirty one years later, things have mellowed and now I find myself somewhere in between the AI approach and connectionism, the new name for neural networks, but certainly closer to the latter. Research has shown that babies start with a lot more than was previously guessed and a major question is how to mesh learning with innate structures. My bias has always been to see learning as primary and this will become clearer in the design of my learning brain, called PURR-PUSS, or PP for short.
PP evolved from an earlier learning machine called STeLLA. For STeLLA, happenings in its world were of two types, patterns and actions. A pattern was divisible into features, and weights were attached to the features, as in Rosenblatt's famous "perceptron". Patterns were mainly seen as visual input and the task facing STeLLA was formulated in a visual form
STeLLA's Task
You are sitting in a dark room. There is a horizontal row of white lights in front of you (input pattern), each light being ON or OFF at any instant. Below the lights a row of push-buttons (actions) lie within your reach and these may be pressed, one at a time, in any sequence. There is nothing else but a pair of coloured lights below the buttons. One of these is green (reward) and the other is red (punishment). Your task is to cause the green light to flash on as often as possible without the red light coming on.
The task is not well defined, but nor are ordinary human tasks, like becoming good at something. We are not told how often the green light could or should be made to come on or how serious the red light is. The numbers of white lights and push buttons will be different for different versions of the task. When we try out STeLLA with a task, we program the way the white lights and the coloured lights change with the button pushes. Different "world programs" give the task different degrees of difficulty. Once we have shown that STeLLA can handle the task of a particular difficulty of world program, we can devise a world program which introduces a new level of difficulty and see what has to be done to the design of STeLLA to enable it to tackle the task with the new world program, without losing its ability with the older world programs. This process of increasing task difficulty continues to the present day and it led to the major change from STeLLA to PURR-PUSS, as we shall see.
STeLLA made simple associations between patterns (of the row of lights) and actions (button presses), called pattern-action pairs. A pattern-action pair recorded the fact that an action had been executed immediately following the seeing of a pattern. Now, after the action of a pattern-action pair had been executed (button pressed), a new pattern of lights would usually follow. First a pattern, then an action chosen, then a pattern seen, then another action chosen, and so on. We could write this sequence thus: p-a..p-a..p-a..p-a..p-a..p …
In STeLLA's memory a network was formed of pattern-action pairs connected to patterns that had followed them. So if, pattern-action pair-1 was followed by pattern-A in STeLLA's world, then there would be a one-way connection from pattern-action pair-1 to pattern-A in STeLLA's memory. If the reward light came on when the action of a pattern-action pair was executed then the action was marked in memory as rewarded. So the memory of STeLLA consisted of a network of pattern-action pairs connected to patterns, where each pattern may be the pattern of a number of pattern-action pairs. A collection of pattern-action pairs with a common pattern is called a node. Some of the pattern-action pairs are marked as rewarded. It is important that the reader sees the relation between nodes and pattern-action pairs, so Figure 1 is given to illustrate the relation by showing a possible fragment of STeLLA's memory. Sometimes it will be more convenient to talk about pattern-action pairs and sometimes nodes will be preferable.
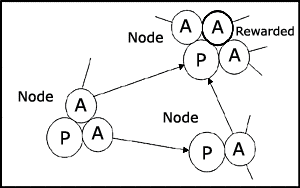 Figure 1 (left). Each node consists of a pattern P and one or more actions A. It can also be seen as one or more P-A pairs with the same P. Each connection from a node to a node goes from an action of the first node to the pattern of the second node. The figure could be a fragment of STeLLA's memory.
Figure 1 (left). Each node consists of a pattern P and one or more actions A. It can also be seen as one or more P-A pairs with the same P. Each connection from a node to a node goes from an action of the first node to the pattern of the second node. The figure could be a fragment of STeLLA's memory.
When STeLLA chose a particular action for a particular pattern, it was choosing an action of a particular node, or a particular pattern-action pair, in the network of its memory. From that pattern-action pair in its memory, paths led through other patterns and their actions to rewarded pattern-action pairs. STeLLA could then choose shorter, stronger paths to get back to rewarded pattern-action pairs. The strength of reward on a pattern-action pair was decreased if it occurred again without getting reward, and it was increased if it occurred again with reward. Connections between nodes also had variable strengths. To take a simple example, if pattern-action pair-1 could be followed by either the pattern of node-A or the pattern of node-B, then there would be two one-way connections from pattern-action pair-1, one to node-A and the other to node-B. The strengths of these two connections were varied to represent the probabilities that pattern-action pair-1 was followed by node-A and node-B respectively.
When STeLLA's task included the red, punishment light, it was used to mark actions on nodes in the same way as the reward light, but punished pattern-action pairs inhibited STeLLA from going along paths instead of encouraging it.
STeLLA's memory told it the best way to go to get reward as soon as possible, and to avoid punishment. This was done by a process I call leakback. This is how it works. Imagine that STELLA's memory is a network of interconnected pipes. The pipe connecting the action of one node to a second node has a diameter which varies according to the strength of that connection. A stronger connection means a larger pipe. Here I have to introduce a slight complication.
Each node is a little container which lets liquid enter from pipes that connect to nodes that follow that node, and lets liquid run out through pipes that connect to nodes that came before that node. I should emphasise that if there is a one-way connection from an action in one node to the pattern of another node, then the pipe representing that connection only allows liquid to flow backwards through it. A rewarded action of a node has an additional input from a tap that lets liquid into the container according to the strength of its reward. A punished action of a node has an outlet which lets liquid escape from the container at a rate which increases with the strength of the punishment. In Figure 2, I have redrawn Figure 1 with pipes instead of connections. Notice that the allowed flows through the pipes in Figure 2 is in the opposite direction to arrows showing connections in Figure 1.
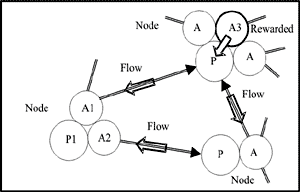 Figure 2 (left). This is the same as Figure 1 with pipes replacing connections and hollow arrows showing the direction of liquid flow for leakback.
Figure 2 (left). This is the same as Figure 1 with pipes replacing connections and hollow arrows showing the direction of liquid flow for leakback.
Looking closely at Figure 2, we see that liquid can flow from the rewarded action A3 in the top right node to the pattern of that node. Then it can flow directly to action A1 of the node on the left, and also it can flow via the node at the bottom right to the action A2 of the node on the left. Let us suppose, that STeLLA is seeing the pattern corresponding to P1 in the node on the left of Figure 2. If the flow, i.e. leakback, from the top node to the left node is greater than the flow via the bottom right node, then STeLLA will choose the action A1 that receives the direct flow; but if the flow to action A2 via the node on the bottom right is stronger, STeLLA will choose that action, A2. Of course, when there are hundreds of nodes and many actions of nodes are rewarded or punished, the flows will be very complicated to calculate, but STeLLA will still choose the action which has the strongest flow. If the pipe diameters used for the calculations are varied correctly, then the choices of STeLLA can be governed by expectations of reward derived from the best estimates of mathematical probabilities. For various reasons, including the fact that the STeLLA tasks do not often correspond to statistically stationary environments, the choices of action will often be sub-optimal, and sometimes downright stupid!
STeLLA planned future paths by means of special memory matrices, one for each action, that predicted the next pattern, given the present pattern and action. Plans are made in a different way in PURR-PUSS using its main memory, so I will not mention STeLLA's planning method any further. The simple idea behind planning is that when the system is about to choose an action, it explores into the future with its memory and if this leads to a path to reward, then it tries to keep to that path. The plan is made step by step: first the next action is chosen, then it predicts the next pattern, chooses the next action, predicts the next pattern, and so on until a rewarded action is found in its memory. The trace of a successful path through its memory is used to bias its decisions until the goal is reached or the predicted patterns fail to be realized. Planning is important because it can lead to the discovery of new paths that had not been taken before.
The earliest description of STeLLA can be found in the Downloads section as STELLA.doc. A later description of STeLLA as A Learning Machine in the Context of the General Control Problem, was published in the Proceedings of the 3rd IFAC Congress, London (1966) pp.342-9 by Brian R. Gaines and me. In this latter paper, STeLLA is given a car-steering problem on a road with camber and slippage, and is shown to learn the task satisfactorily.
Limitations of STeLLA
The main limitation of STeLLA was lack of sequential strength. It couldn't learn a sequence of events without there being a strong possibility that a similar sequence would take over. It could hear "Two times two equals four" a thousand times and have that well learned, but when you started to teach it "Three times two equals six", the two sequences would become hopelessly entangled. After "Two" and also after "Three" it expects "times", which is all right. After "times" it is expecting "two" and then "equals". So far so good, but now the trouble starts. After "equals" it expects either "four" or "six"., and its memory doesn't tell it whether it has come along the "Two times two equals" sequence or the "Three times two equals" sequence, so its memory isn't telling it whether the next word should be "four" or "six". This is what I mean by not having sequential strength.
Language is full of sequences in the form of phrases and sentences so it is not possible for STeLLA to learn even the simplest phrases without getting them muddled up with others. STeLLA could do the car steering task, mentioned above, because every decision could be taken on the basis of its last sensory input. It didn't need to know what had happened just before. Real driving is much more sequential. It is essential that a real driver of a car keeps the context of what is happening in mind. If you have just passed a speed limit sign, you must keep that in mind — and a hundred other things.
We can divide up the STeLLA behaviour into two parts, what happens between pattern and action, and what happens between action and pattern. When STeLLA sees the pattern of lights, it has to choose a button to push. This choice is decided by its control policy that uses leakback to calculate expectations of reward for the different buttons. The choice of button is also influenced by its plans and, to make a plan, STeLLA has to predict what the next pattern of lights will be when it pushes a button. In the case of a real robot, what it will see next after it does an action is determined by its world. So, to predict what the next pattern of lights will be, STeLLA has to "guess" what the world behind the buttons and lights will do. We can say that STeLLA needs a model of the world which reacts to button pushes by changing the pattern of lights. In the car-steering example mentioned above, the world is the car and the road with turns and skids, all of which contribute to what the next position and angle of the car will be, and hence what the pattern of lights will be.
STeLLA's model of the world also lacked sequential strength, because it used only the last pattern to predict the effect of a button push. Its control policy did at least string together pattern-action pairs, even if that stringing together was weak. The weakness of STeLLA's predictor was more serious so we tackled that first. The struggles that I and my postgraduate students had with this problem can be seen in the first of a series of Man-Machine Studies reports, which is available as UC-DSE-1.doc from the Downloads section of this Web Page. Our aim was to model a world that had the structure of a finite state machine. Eventually, with crucial input from John G. Cleary, a predictor called PUSS was devised for STeLLA. PUSS stood for "Predictor Using Slide and Strings" which described its mechanism at that time.
To cut a long story short, PUSS was so successful that STeLLA was abandoned and a new system was constructed, called PURR-PUSS. The PURR stood for "Purposeful Unprimed Rewardable Robot" and the whole system was based on PUSSes. To our surprise, PURR-PUSS turned out to have more sequential strength than we expected. Eventually we would show that PURR-PUSS had the sequential strength of a Universal Turing Machine, the most that was possible of any system. Nevertheless, PURR-PUSS retained key features of STeLLA, including leakback.